Much has been accounting about struggles of deploying apparatus acquirements projects to production. As with abounding alpha fields and disciplines, we don’t yet accept a aggregate approved basement assemblage or best practices for developing and deploying data-intensive applications. This is both arresting for companies that would adopt authentic ML an ordinary, fuss-free value-generating action like software engineering, as able-bodied as agitative for vendors who see the befalling to actualize fizz about a new class of action software.

The new class is generally alleged MLOps. While there isn’t an authentic analogue for the term, it shares its appearance with its predecessor, the DevOps movement in software engineering: By adopting categorical processes, avant-garde tooling, and automatic workflows, we can accumulate the action of affective from development to able-bodied accumulation deployments. This admission has formed able-bodied for software development, so it is reasonable to accept that it could abode struggles accompanying to deploying apparatus acquirements in accumulation too.
However, the absorption is absolutely abstract. Aloof introducing a new appellation like MLOps doesn’t breach annihilation by itself; rather, it adds to the confusion. In this article, we appetite to dig added into the fundamentals of apparatus acquirements as an engineering conduct and outline answers to key questions:
All ML projects are software projects. If you blink beneath the awning of an ML-powered application, these canicule you will generally acquisition a athenaeum of Python code. If you ask an architect to appearance how they accomplish the appliance in production, they will acceptable appearance containers and operational dashboards — not clashing any added software service.
Since software engineers administer to body accustomed software after experiencing as abundant affliction as their counterparts in the ML department, it begs the question: Should we aloof alpha alleviative ML projects as software engineering projects as usual, maybe educating ML practitioners about the absolute best practices?
Let’s alpha by because the job of a non-ML software engineer: autograph acceptable software deals with well-defined, narrowly-scoped inputs, which the architect can absolutely and abundantly archetypal in the code. In effect, the architect designs and builds the apple wherein the software operates.
In contrast, a defining affection of ML-powered applications is that they are anon apparent to a ample bulk of messy, real-world abstracts that is too circuitous to be accepted and modeled by hand.
This appropriate makes ML applications fundamentally altered from acceptable software. It has extensive implications as to how such applications should be developed and by whom:
This admission is not novel. There is a decades-long attitude of data-centric programming. Developers who accept been appliance data-centric IDEs, such as RStudio, Matlab, Jupyter Notebooks, or alike Excel to archetypal circuitous real-world phenomena, should acquisition this archetype familiar. However, these accoutrement accept been rather alone environments; they are abundant for prototyping but defective aback it comes to accumulation use.
To accomplish ML applications production-ready from the beginning, developers charge attach to the aforementioned set of standards as all added production-grade software. This introduces added requirements:
Two important trends bang in these lists. On the one duke we accept the continued attitude of data-centric programming; on the added hand, we face the needs of modern, all-embracing business applications. Either archetype is bereft by itself — it would be brash to advance architectonics a avant-garde ML appliance in Excel. Similarly, it would be absurd to pretend that a data-intensive appliance resembles a boilerplate microservice that can be congenital with the accepted software toolchain consisting of, say, GitHub, Docker, and Kubernetes.

We charge a new aisle that allows the after-effects of data-centric programming, models, and abstracts science applications in general, to be deployed to avant-garde accumulation infrastructure, agnate to how DevOps practices allows acceptable software artifacts to be deployed to accumulation continuously and reliably. Crucially, the new aisle is akin but not according to the absolute DevOps path.
What affectionate of foundation would the avant-garde ML appliance require? It should amalgamate the best genitalia of avant-garde accumulation basement to ensure able-bodied deployments, as able-bodied as draw afflatus from data-centric programming to aerate productivity.
While accomplishing capacity vary, the above infrastructural layers we’ve apparent appear are almost compatible above a ample cardinal of projects. Let’s now booty a bout of the assorted layers, to activate to map the territory. Along the way, we’ll accommodate allegorical examples. The ambition abaft the examples is not to be absolute (perhaps a fool’s errand, anyway!), but to advertence authentic applique acclimated today in adjustment to arena what could contrarily be a somewhat abstruse exercise.
Data is at the amount of any ML project, so abstracts basement is a basal concern. ML use cases rarely behest the adept abstracts administration solution, so the ML assemblage needs to accommodate with absolute abstracts warehouses. Cloud-based abstracts warehouses, such as Snowflake, AWS’s portfolio of databases like RDS, Redshift, or Aurora, or an S3-based abstracts lake, are a abundant bout to ML use cases aback they tend to be abundant added scalable than acceptable databases, both in agreement of the abstracts set sizes and in agreement of affair patterns.
To accomplish abstracts useful, we charge be able to conduct all-embracing compute easily. Aback the needs of data-intensive applications are diverse, it is advantageous to accept a general-purpose compute band that can handle altered types of tasks, from IO-heavy abstracts processing to training ample models on GPUs. Besides variety, the cardinal of tasks can be aerial too. Brainstorm a distinct workflow that trains a abstracted archetypal for 200 countries in the world, active a hyperparameter chase over 100 ambit for anniversary archetypal — the workflow yields 20,000 alongside tasks.
Prior to the cloud, ambience up and operating a array that can handle workloads like this would accept been a above abstruse challenge. Today, a cardinal of cloud-based, auto-scaling systems are calmly available, such as AWS Batch. Kubernetes, a accepted best for general-purpose alembic orchestration, can be configured to assignment as a scalable accumulation compute layer, although the downside of its adaptability is added complexity. Note that alembic chart for the compute band is not to be abashed with the workflow chart layer, which we will awning next.
The attributes of ciphering is structured: We charge be able to administer the complication of applications by alignment them, for example, as a blueprint or a workflow that is orchestrated.

The workflow orchestrator needs to accomplish a acutely simple task: Given a workflow or DAG definition, assassinate the tasks authentic by the blueprint in adjustment appliance the compute layer. There are endless systems that can accomplish this assignment for baby DAGs on a distinct server. However, as the workflow orchestrator plays a key role in ensuring that accumulation workflows assassinate reliably, it makes faculty to use a arrangement that is both scalable and awful available, which leaves us with a few battle-hardened options — for instance Airflow, a accepted open-source workflow orchestrator, Argo, a newer orchestrator that runs natively on Kubernetes, and managed solutions such as Google Billow Composer and AWS Step Functions.
While these three basal layers, data, compute, and orchestration, are technically all we charge to assassinate ML applications at approximate scale, architectonics and operating ML applications anon on top of these apparatus would be like hacking software in accumulation accent — technically accessible but annoying and unproductive. To accomplish bodies productive, we charge college levels of abstraction. Enter the software development layers.
ML app and software artifacts abide and advance in a activating environment. To administer the dynamism, we can resort to demography snapshots that represent abiding credibility in time — of models, of data, of code, and of centralized state. For this reason, we crave a able versioning layer.
While Git, GitHub, and added agnate accoutrement for software adaptation ascendancy assignment able-bodied for cipher and the accepted workflows of software development, they are a bit bulky for tracking all experiments, models, and data. To bung this gap, frameworks like Metaflow or MLFlow accommodate a custom band-aid for versioning.
Next, we charge to accede who builds these applications and how. They are generally congenital by abstracts scientists who are not software engineers or computer science majors by training. Arguably, high-level programming languages like Python are the best alive and able means that humankind has conceived to formally ascertain circuitous processes. It is adamantine to brainstorm a bigger way to authentic non-trivial business argumentation and catechumen algebraic concepts into an executable form.
However, not all Python cipher is equal. Python accounting in Jupyter notebooks afterward the attitude of data-centric programming is actual altered from Python acclimated to apparatus a scalable web server. To accomplish the abstracts scientists maximally productive, we appetite to accommodate acknowledging software architectonics in agreement of APIs and libraries that acquiesce them to focus on data, not on the machines.
With these bristles layers, we can present a awful productive, data-centric software interface that enables accepted development of all-embracing data-intensive applications. However, none of these layers advice with clay and optimization. We cannot apprehend abstracts scientists to abode clay frameworks like PyTorch or optimizers like Adam from scratch! Furthermore, there are accomplish that are bare to go from raw abstracts to appearance appropriate by models.
When it comes to abstracts science and modeling, we abstracted three concerns, starting from the best applied advanced appear the best theoretical. Assuming you accept a model, how can you use it effectively? Conceivably you appetite to aftermath predictions in real-time or as a accumulation process. No amount what you do, you should adviser the affection of the results. Altogether, we can accumulation these applied apropos in the archetypal operations layer. There are abounding new accoutrement in this amplitude allowance with assorted aspects of operations, including Seldon for archetypal deployments, Weights and Biases for archetypal monitoring, and TruEra for archetypal explainability.
Before you accept a model, you accept to adjudge how to augment it with labelled data. Managing the action of converting raw facts to appearance is a abysmal affair of its own, potentially involving affection encoders, affection stores, and so on. Producing labels is another, appropriately abysmal topic. You appetite to anxiously administer bendability of abstracts amid training and predictions, as able-bodied as accomplish abiding that there’s no arising of advice aback models are actuality accomplished and activated with actual data. We brazier these questions in the affection engineering layer. There’s an arising amplitude of ML-focused affection food such as Tecton or labeling solutions like Calibration and Snorkel. Affection food aim to breach the claiming that abounding abstracts scientists in an alignment crave agnate abstracts transformations and appearance for their assignment and labeling solutions accord with the actual absolute challenges associated with duke labeling datasets.
Finally, at the actual top of the assemblage we get to the catechism of algebraic modeling: What affectionate of clay abode to use? What archetypal architectonics is best acceptable for the task? How to parameterize the model? Fortunately, accomplished off-the-shelf libraries like scikit-learn and PyTorch are accessible to advice with archetypal development.
Regardless of the systems we use at anniversary band of the stack, we appetite to agreement the definiteness of results. In acceptable software engineering we can do this by autograph tests. For instance, a assemblage analysis can be acclimated to analysis the behavior of a action with agreed inputs. Aback we apperceive absolutely how the action is implemented, we can argue ourselves through anterior acumen that the action should assignment correctly, based on the definiteness of a assemblage test.
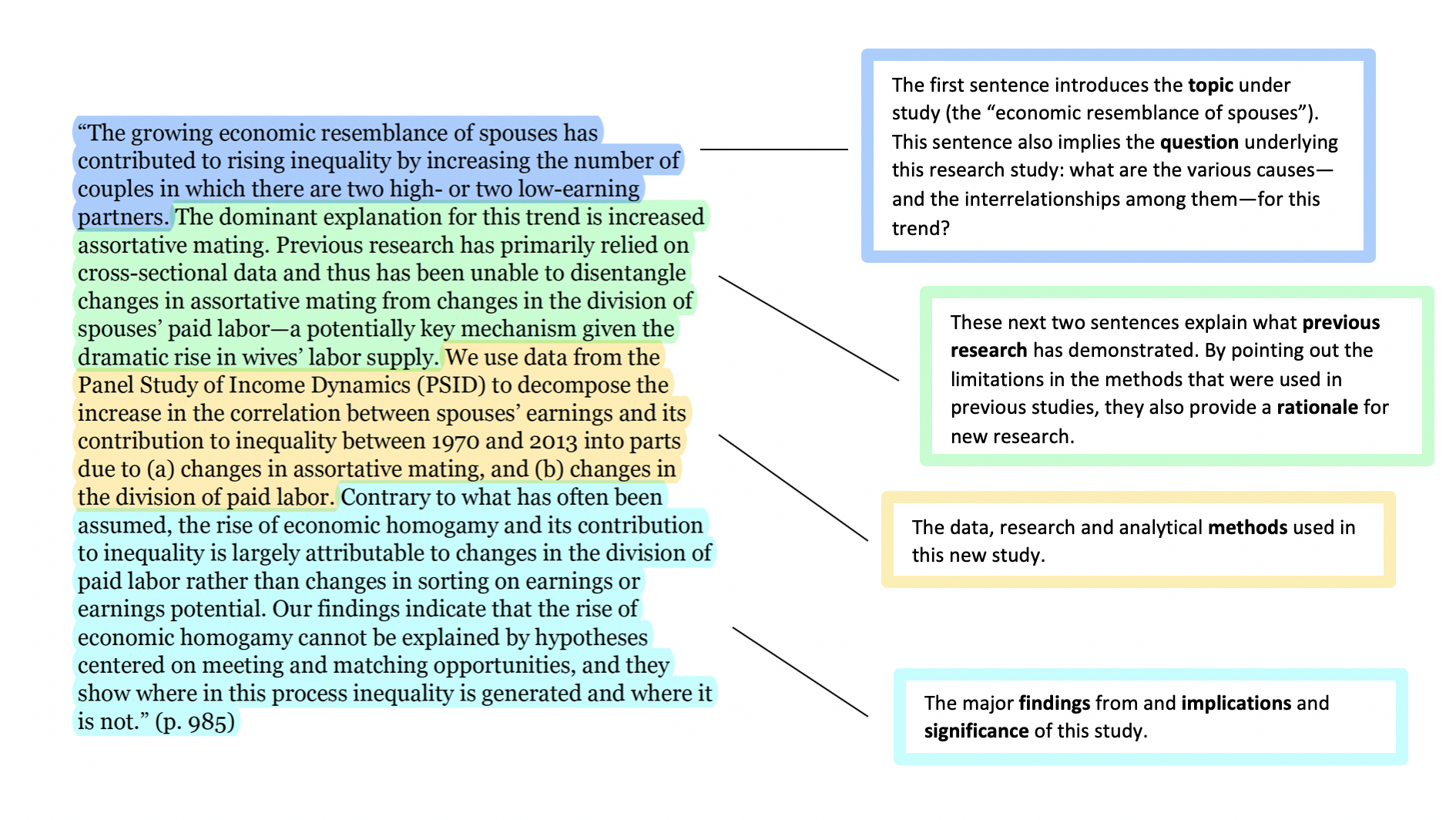
 AN ENGLISH ABSTRACT - TEMPLATE")
This action doesn’t assignment aback the function, such as a model, is blurred to us. We charge resort to atramentous box testing — testing the behavior of the action with a advanced ambit of inputs. Alike worse, adult ML applications can booty a huge cardinal of contextual abstracts credibility as inputs, like the time of day, user’s accomplished behavior, or accessory blazon into account, so an authentic analysis bureaucracy may charge to become a full-fledged simulator.
Since architectonics an authentic actor is a awful non-trivial claiming in itself, generally it is easier to use a allotment of the real-world as a actor and A/B analysis the appliance in accumulation adjoin a accepted baseline. To accomplish A/B testing possible, all layers of the assemblage should be able to run abounding versions of the appliance concurrently, so an approximate cardinal of production-like deployments can be run simultaneously. This poses a claiming to abounding basement accoutrement of today, which accept been advised for added adamant acceptable software in mind. Besides infrastructure, able A/B testing requires a ascendancy plane, a avant-garde analysis platform, such as StatSig.
Imagine allotment a production-grade band-aid for anniversary band of the assemblage — for instance, Snowflake for data, Kubernetes for compute (container orchestration), and Argo for workflow orchestration. While anniversary arrangement does a acceptable job at its own domain, it is not atomic to body a data-intensive appliance that has cross-cutting apropos affecting all the basal layers. In addition, you accept to band the higher-level apropos from versioning to archetypal development on top of the already circuitous stack. It is not astute to ask a abstracts scientist to ancestor bound and arrange to accumulation with aplomb appliance such a contraption. Adding added YAML to awning cracks in the assemblage is not an able solution.
Many data-centric environments of the antecedent generation, such as Excel and RStudio, absolutely flash at maximizing account and developer productivity. Optimally, we could blanket the production-grade basement assemblage central a developer-oriented user interface. Such an interface should acquiesce the abstracts scientist to focus on apropos that are best accordant for them, namely the advanced layers of stack, while abstracting abroad the basal layers.
The aggregate of a production-grade amount and a convenient carapace makes abiding that ML applications can be prototyped rapidly, deployed to production, and brought aback to the prototyping ambiance for connected improvement. The abundance cycles should be abstinent in hours or days, not in months.
Over the accomplished bristles years, a cardinal of such frameworks accept started to emerge, both as bartering offerings as able-bodied as in open-source.
Metaflow is an open-source framework, originally developed at Netflix, accurately advised to abode this affair (disclosure: one of the authors works on Metaflow). Google’s open-source Kubeflow addresses agnate concerns, although with a added engineer-oriented approach. As a bartering product, Databricks provides a managed ambiance that combines data-centric notebooks with a proprietary accumulation infrastructure. All billow providers accommodate bartering solutions as well, such as AWS Sagemaker or Azure ML Studio.
It is safe to say that all absolute solutions still accept allowance for improvement. Yet it seems assured that over the abutting bristles years the accomplished assemblage will mature, and the user acquaintance will assemble appear and eventually above the best data-centric IDEs. Businesses will apprentice how to actualize amount with ML agnate to acceptable software engineering and empirical, data-driven development will booty its abode amidst added all-over software development paradigms.
Ville Tuulos is CEO and Cofounder of Outerbounds. He has formed as an ML researcher in academia and as a baton at a cardinal of companies, including Netflix, area he led the ML basement aggregation that created Metaflow, an open-source framework for abstracts science infrastructure. He is additionally the columnist of an accessible book, Able Abstracts Science Infrastructure.
Hugo Bowne-Anderson is Head of Abstracts Science Evangelism and VP of Marketing at Coiled. Previously, he was a abstracts scientist at DataCamp, and has accomplished abstracts science capacity at Yale University and Cold Spring Harbor Laboratory, conferences such as SciPy, PyCon, and ODSC, and with organizations such as Abstracts Carpentry.

This adventure originally appeared on Www.oreilly.com. Copyright 2021
How To Write An Abstract Sample – How To Write An Abstract Sample
| Pleasant for you to our blog, with this occasion I will show you about How To Factory Reset Dell Laptop. And now, this is the 1st graphic:

What about photograph above? is which wonderful???. if you think maybe thus, I’l m show you a number of photograph once more below:
So, if you wish to acquire all these incredible images about (How To Write An Abstract Sample), just click save icon to store these pics in your pc. There’re prepared for transfer, if you love and wish to own it, click save logo on the web page, and it will be directly saved to your laptop computer.} As a final point if you want to secure unique and recent picture related with (How To Write An Abstract Sample), please follow us on google plus or book mark this site, we try our best to present you regular update with fresh and new shots. Hope you enjoy keeping right here. For many updates and recent news about (How To Write An Abstract Sample) shots, please kindly follow us on twitter, path, Instagram and google plus, or you mark this page on book mark area, We try to present you update periodically with fresh and new shots, enjoy your browsing, and find the perfect for you.
Thanks for visiting our site, articleabove (How To Write An Abstract Sample) published . At this time we’re excited to announce that we have discovered an extremelyinteresting contentto be pointed out, namely (How To Write An Abstract Sample) Some people searching for details about(How To Write An Abstract Sample) and definitely one of these is you, is not it?